Composition Patterns That Work

Publish Date August 15, 2025

One of MCP’s most powerful features is enabling LLMs to combine tools into solutions. In this section I want to give you ideas for how to craft effective composition patterns.
Three principles for composable tools
1. Predictable contracts Each tool has clear inputs and outputs. When AnalyzeDocumentationQuality returns a QualityReport, the LLM knows exactly what fields it contains and can confidently access .Issues or .Score.
2. Independent operation CheckLinkValidity doesn’t need AnalyzeDocumentationQuality to run first. Each tool is self-contained, taking a document path and returning complete results.
3. Complementary purposes Each tool provides a different lens on the same problem space. Quality analysis, link checking, and readability metrics all contribute to understanding documentation health without overlapping.
Sequential patterns
Sequential composition creates workflows where each tool’s output enhances the next step.
Pattern: Progressive refinement
AnalyzeDocumentationQuality(doc)
→ identifies missing sections
→ CheckLinkValidity(doc, focus_on_sections=identified_sections)
→ checks links in problem areas first
→ GenerateImprovementReport(quality_results, link_results)
Pattern: Filter and focus
ExtractDocumentStructure(doc)
→ identifies all code blocks
→ ValidateCodeExamples(doc, languages=found_languages)
→ validates only relevant languages
→ CalculateCodeCoverage(validation_results)
Each step narrows focus based on previous discoveries, allowing LLMs to explain their reasoning clearly.
Parallel patterns
Parallel composition leverages independence for efficiency.
Pattern: Comprehensive analysis
Parallel:
├── AnalyzeDocumentationQuality(doc)
├── CheckLinkValidity(doc)
├── CalculateReadabilityMetrics(doc)
└── ExtractDocumentStructure(doc)
Then: CombineIntoReport(all_results)
Pattern: Multi-perspective validation
For each code example in parallel:
├── CheckSyntax(example)
├── CheckImports(example)
├── CheckOutput(example)
└── CheckComplexity(example)
No tool depends on another’s output. If one fails, others still provide value, allowing LLMs to optimize for speed without worrying about ordering.
The role of structured outputs
Structured outputs enable reliable composition. When tools return structured data:
- LLMs know what fields are available
- Results can be filtered intelligently
- Tools can be chained predictably
Code:
// Structured output with clear fields for downstream consumption
type QualityReport struct {
Score float64
Issues []Issue
MissingSections []string
}
// Organized output - ready for composition
type LinkReport struct {
BrokenLinks []BrokenLink
BySection map[string][]BrokenLink // Pre-grouped by document section
BySeverity map[string][]BrokenLink // "critical", "warning", "info"
}Code language: JavaScript (javascript)Each tool can efficiently access the exact subset of data it needs:
- The MCP client asks: “What critical links need fixing in the API docs?”
- LLM combines: report.BySection[“api-docs”] ∩ report.BySeverity[“critical”]
- No filtering through hundreds of links needed
Composition best practices
- Design tools that transform, not just extract
- AnalyzeReadability() ReadabilityReport provides rich data for next steps
- Better than simple GetWordCount() int
- Organize outputs for easy filtering Pre-group data by common use cases (by section, by severity) so downstream tools can efficiently access what they need.
- Provide both summary and detail Let LLMs choose the appropriate level for their current task.
Code:
type QualityReport struct {
Summary Summary // For quick decisions
Details []Issue // For deep analysis
Suggestions []Suggestion // For next steps
}Code language: JavaScript (javascript)- Use consistent identification All tools should use the same parameter names and types for common inputs like file paths.
Tip
Useful composition doesn’t happen by stacking iterations, it emerges from clear intentions, predictable contracts, and precise thinking about how tools can work together.
When intention meets reality, aka iterations
How do we evolve without losing sight of the intention we started out with? How do we adapt to real needs without becoming Monica’s FlexiServer?
Evolving without losing focus
The key to healthy evolution is treating our intention as a compass, not a cage. It guides direction while allowing for growth. Every successful MCP server evolves, but the ones that thrive do so deliberately.
Signs of healthy evolution:
- New tools make existing ones more valuable
- Original users get more power without more complexity
- Each addition serves the core intention better
- LLMs can still explain the server’s purpose in one sentence
Signs of drift:
- New tools serve different user types
- Original tools feel disconnected from new ones
- We’re adding parameters to make tools do double duty
- LLMs hedge when describing what the server does
The three patterns for evolution: Deepen, Fork, Pivot
1. Deepen (most common)
Intention stays the same, but we serve it better:
// V1: Help developers understand code
func ExplainFunction(name string) (string, error)
// V2: Same intention, deeper capability
func ExplainFunction(name string, detail Level) (Explanation, error)
func VisualizeCallGraph(name string) (GraphData, error)
func ExplainWithExamples(name string) (ExplanationWithCode, error)
Deepening feels natural because:
- Original users get more value
- New tools complement existing ones
- The core intention gets stronger, not diluted
2. Fork (when users pull in new directions)
Users want something adjacent but different:
// Original: DocQualityAdvisor – helps understand docs
// Users want: “Can it fix the broken links it finds?”
// Wrong: Add fixing to DocQualityAdvisor (breaks read-only constraint)
// Right: Create DocFixer as a sibling server
Forking preserves clarity:
- Original server stays focused
- New server has its own clear intention
- They compose beautifully together
- Neither suffers from scope creep
3. Pivot (rare, when intention was wrong)
Only when we discover our original intention missed the mark entirely:
// Started: “Help developers write better commit messages”
// Discovered: They actually needed “Help developers understand what changed”
// Pivot: Refocus on change analysis, not message writing
Pivoting requires honesty:
- Admit the original intention was off
- Define a new, clearer intention
- Potentially rename/rebrand
- Communicate the change clearly
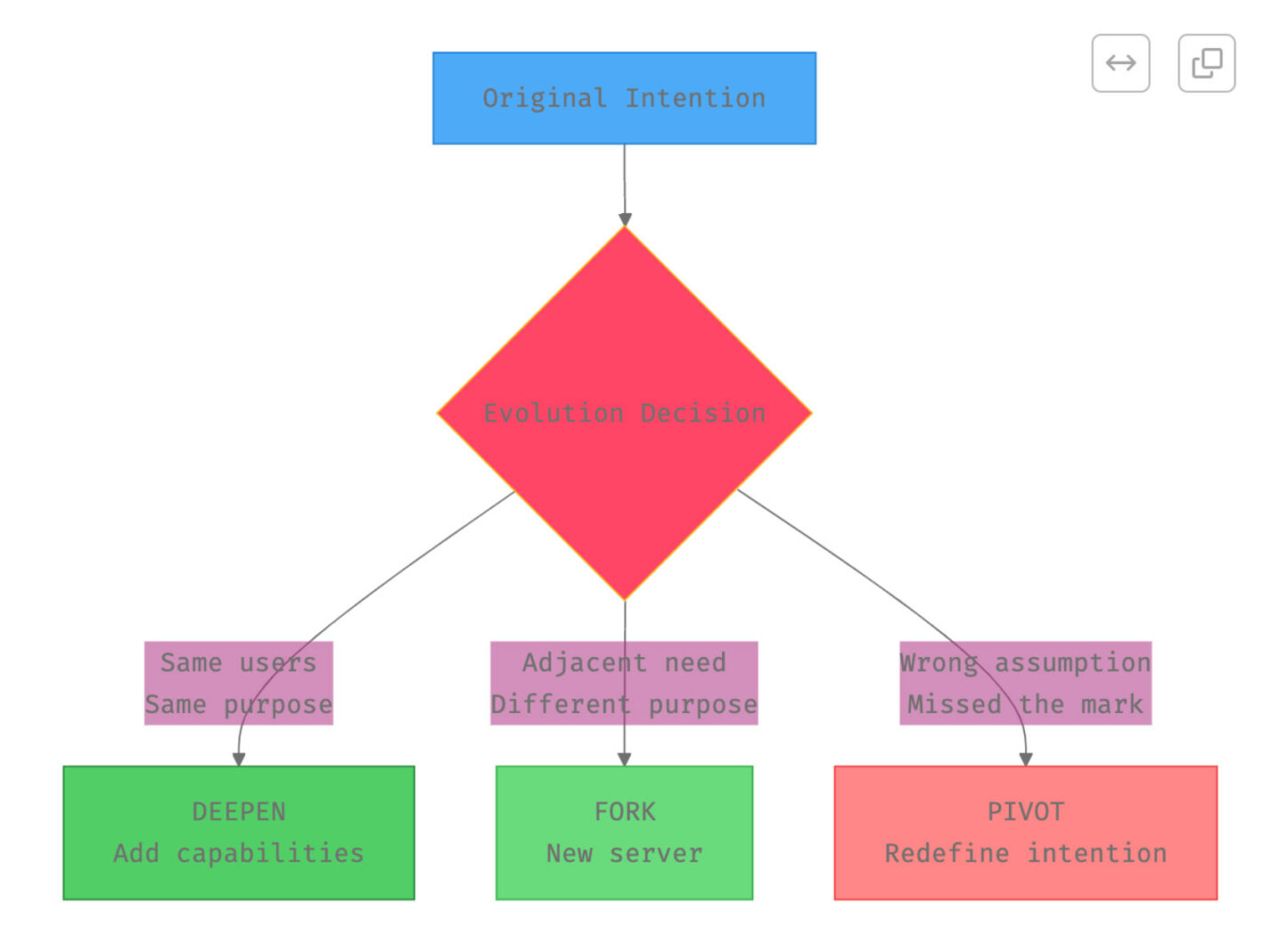
Version evolution example
Let’s follow a server through realistic growth:
Version 1.0: Personal use
Intention: Help me find security issues in my Node.js projects
Tools:
– FindHardcodedSecrets()
– CheckDependencyVulnerabilities()
– IdentifyInsecurePatterns()
Version 2.0: Team adoption (Deepen)
Same intention, expanded for team needs:
– FindHardcodedSecrets(severity Level)
– CheckDependencyVulnerabilities(includeDevDeps bool)
– IdentifyInsecurePatterns(customRules []Rule)
– GenerateSecurityReport() // New: aggregate findings
Version 3.0: Adjacent need emerges (Fork decision)
Users: “Can it automatically update vulnerable dependencies?”
Decision point:
– Updating != Finding (different WHAT)
– Requires write access (different CONSTRAINT)
– Solution: Fork into SecurityScanner + SecurityFixer
Each version deepened value for the original use case without losing focus.
When to say no to ideas that don’t fit
The hardest part of evolution might be saying no to good ideas that don’t fit. Here’s some guidance:
Immediate no:
- Violates core constraints (write access for read-only tool)
- Serves different users (enterprise features for personal tool)
- Requires architecture change (real-time for batch tool)
Consider forking when:
- Great idea but different intention
- Would help users but breaks existing patterns
- Valuable but changes core assumptions
Consider deepening when:
- Makes existing tools more powerful
- Serves same users better
- Respects all constraints
- Natural extension of current capabilities
Real example: Eduardo’s evolution decisions
Remember Eduardo’s decision to keep “fixing” separate from “analysis”? Here’s how he applied the same filter to feature requests:
Request: “Add README template generator” → No, generating != analyzingRequest: “Add API example validation” → Yes, code quality IS documentation quality
The filter works consistently: features that serve the core intention get deepened, others get redirected.
Conclusion: trust the process
We’ve seen three developers, three approaches, three outcomes. Monica chased flexibility and created confusion. Bruno mapped existing APIs and created fragmentation. Eduardo started with intention and created clarity.
And the difference really wasn’t skill or effort, it was mindset and process.
The path forward
Building MCP servers with AI in the loop requires us to flip our hard-earned instincts. Before we minimized constraints to stay adaptive, to favor continuous flexibility through iteration. Now we maximize constraints upfront to maximize effectiveness.
The process needed is relatively simple, but requires precision:
- Start with clear intention: before writing code, write the WHO, WHAT, CONSTRAINTS, and WHY
- Let intention guide every decision: server and tool boundaries, feature requests, error messages
- Intentional composition through clarity: predictable tools with structured outputs work together naturally
- Evolve deliberately: deepen to serve better, fork to serve different, pivot when necessary
Your turn
The next time you sit down to build an MCP server (or any agentic system):
- Write your intention statement before your next commit
- Put it in your README as the first thing users see
- Use it to evaluate every decision: “Does this serve our intention?”
- Let it guide your evolution: deepen rather than broaden